あなたの選択した答えは強調表示されています。
問題1 |
ある企業は、複雑な問題解決タスクに対して大規模言語モデル (LLM) の応答品質を向上させたいと考えています。これらのタスクでは、詳細な推論と段階的な説明プロセスが必要です。
これらの要件を満たすプロンプトエンジニアリング手法を選択してください。
方向性刺激プロンプティング (Directional Stimulus Prompting) | |
Few-shot プロンプティング | |
Chain-of-Thought (CoT: 思考の連鎖) プロンプティング | |
Zero-shot プロンプティング |
問題 1 の説明および補足
Chain-of-Thought (CoT: 思考の連鎖) プロンプティング
「Chain-of-Thought (CoT: 思考の連鎖) プロンプティング」 を用いることで、詳細な推論や段階的な説明プロセスを効果的に引き出すことができるため正解です。
00:00

「より礼儀正しく応答してください」 といった形で使用されます。しかしこの手法では、問題解決に必要な段階的推論プロセスや説明展開を明示的に誘導することはできません。そのため、複雑な論理的思考や多段階の推論を必要とするタスクには不十分です。| サービス名 | 特徴 | 主な用途 |
|---|---|---|
| Chain-of-Thought Prompting | モデルに中間推論ステップを言語化させることで 段階的な思考プロセスを可視化し、複雑な問題解決の精度を高める 。 | 複数の計算や論理を順番に行うタスクで有効。 例 : 中学生向けの算数の文章題で「りんごを 20 個、みかんを 3 箱 (1 箱 47 個) 買ったら合計はいくつ ?」と聞くと、モデルが「Step 1: 20 × 1 = 20 個」「Step 2: 3 × 47 = 141 個」「Step 3: 合計 = 161 個」と順に説明して答えを示す。 |
| Few-shot Prompting | プロンプトに少数の例を含めて類似の出力を誘導する。推論過程は出力しないため結論のみを模倣しやすい。 | パターン学習やフォーマット統一が必要なタスクに適用。 例 : 英単語とその日本語訳を 2 つ示し、「banana = ばなな」と続けさせて追加の単語を訳させる。 |
| Zero-shot Prompting | 例を一切提示せずに直接タスクを指示するシンプルな形式。思考過程を明示せず回答のみを出す。 | 一般知識を素早く引き出す質問に適用。 例 : 「東京タワーの高さを教えて」と聞くだけで即座に答えを返させる。 |
| Directional Stimulus Prompting | 出力のトーンやスタイルを方向付ける追加指示を与える。推論の深さより表現形式を制御することに長ける。 | 回答の語調やフォーマット統一が重要な場面で使用。 例 : 「この質問には敬語で丁寧に答えて」と指示し、礼儀正しい日本語で返答させる。 |
問題2 |
ある企業の大規模言語モデル (LLM) で幻覚 (ハルシネーション) が発生しています。
幻覚 (ハルシネーション) を減らす最適な方法を選択してください。
Amazon Bedrock のエージェントを設定して、モデルのトレーニングを監視します。 | |
モデルの推論パラメータである 温度 (temperature) を下げます。 | |
データの前処理を使用して、幻覚 (ハルシネーション) を引き起こすデータを削除します。 | |
幻覚 (ハルシネーション) が発生しないようにトレーニングされた基礎モデル (FM) を使用します。 |
問題 2 の説明および補足
温度 (temperature) : モデルの推論パラメータ
モデルの推論パラメータである 「温度 (temperature)」 を下げることで、生成される回答のランダム性が抑制され、幻覚 (ハルシネーション) を減らすことができるため正解です。
00:00
問題3 |
あるメディア企業は、視聴者の行動と人口統計を分析し、パーソナライズされたコンテンツを推奨したいと考えています。企業はカスタマイズした ML モデルを本番環境にデプロイし、時間の経過とともにモデルの品質が変化するかどうかも監視したいと考えています。
これらの要件を満たす AWS のサービスや機能を選択してください。
Amazon Rekognition | |
Amazon Comprehend | |
Amazon SageMaker Clarify | |
Amazon SageMaker Model Monitor |
問題 3 の説明および補足
Amazon SageMaker Model Monitor
「Amazon SageMaker Model Monitor」 は、本番環境にデプロイした機械学習モデルの品質の変化を監視できるため正解です。
00:00

| 名称 | 特徴 | 主な用途 |
|---|---|---|
| Amazon SageMaker Model Monitor | 本番エンドポイントの入力・出力を収集し、ベースライン統計と比較して データドリフトや品質劣化を自動検知 します。アラーム発報やレポート生成も可能です。 | 継続的モデル監視。例 : 動画配信サービスが「視聴者行動データ」で学習した推薦モデルを 24 時間体制で見守り、異常な推論が出たら運用チームへ通知する。 |
| Amazon Rekognition | 画像・動画の物体検出や顔認識をフルマネージドで実行します。 | メディア分析。例 : 写真から犬や猫を判定し、アルバムを自動分類する。 |
| Amazon SageMaker Clarify | 学習データと推論結果のバイアス計測やモデルの説明可能性レポートを生成します。 | AI の公平性評価。例 : 入試判定モデルが男女で不公平になっていないかを確認する。 |
| Amazon Comprehend | 自然言語処理サービスで、感情分析やエンティティ抽出を API で提供します。 | テキスト分析。例 : 商品レビューから「うれしい」「悲しい」といった感情を集計し、人気商品を把握する。 |
問題4 |
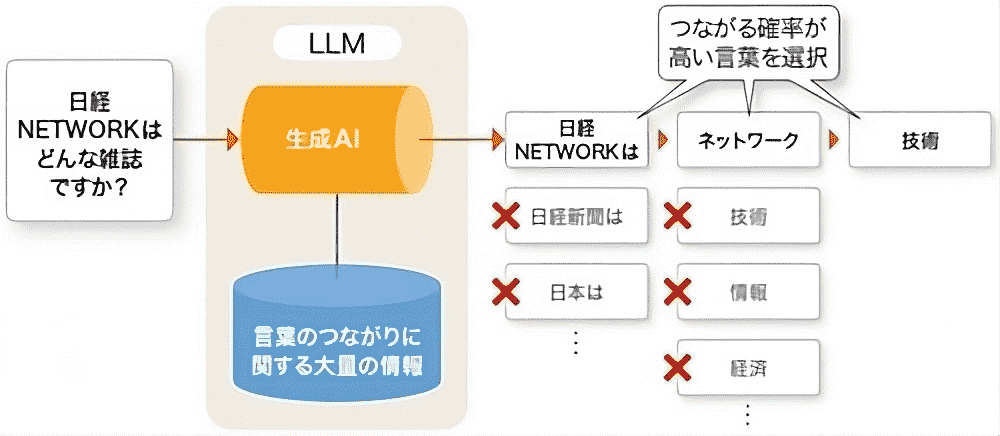
ある企業は、最新のデータを使用することで、基礎モデル (FM) を常に適切なものに保ちたいと考えています。同社は、FM の定期的な更新を含むモデルのトレーニング戦略を実施したいと考えています。
これらの要件を満たすソリューションを選択してください。
潜在空間を活用するトレーニング | |
継続的な事前トレーニング | |
静的トレーニング | |
バッチトレーニング |
問題 4 の説明および補足
継続的な事前トレーニング
「継続的な事前トレーニング」 は最新データを逐次取り込みモデルを常に更新できるため正解です。
00:00
問題5 |
ある企業が AI を活用した履歴書審査システムを構築しました。企業は大規模なデータセットを使用してモデルをトレーニングしましたが、そのデータセットにはすべての属性を代表していない履歴書が含まれていました。
このシナリオが示す責任ある AI の主要な次元を選択してください。
プライバシーとセキュリティ (Privacy and security) | |
透明性 (Transparency) | |
説明可能性 (Explainability) | |
公平性 (Fairness) |
問題 5 の説明および補足
公平性
「公平性 (Fairness)」 の観点から、代表性に欠けるデータセットはモデルに 「バイアス」 を生み、応募者に不公平な評価を与えるため正解です。
00:00

問題6 |
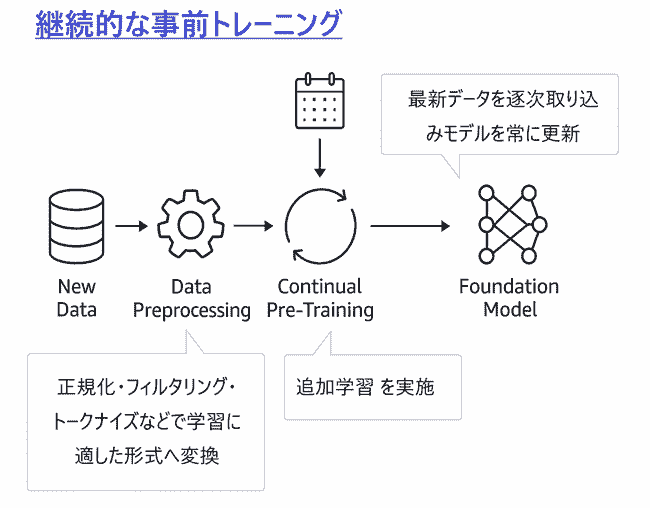
ある企業は、拡張性に優れた AWS サービスを使用して ML システムのパフォーマンスを監視する必要があります。
この要件を満たす AWS サービスを選択してください。
Amazon CloudWatch | |
AWS CloudTrail | |
AWS Config | |
AWS Trusted Advisor |
問題 6 の説明および補足
Amazon CloudWatch で Amazon SageMaker AI をモニタリングするためのメトリクス
「Amazon CloudWatch」 は、リアルタイムメトリクスとアラームを標準で提供し、スケーラブルに ML システムのパフォーマンスを監視できるため正解です。
00:00
問題7 |
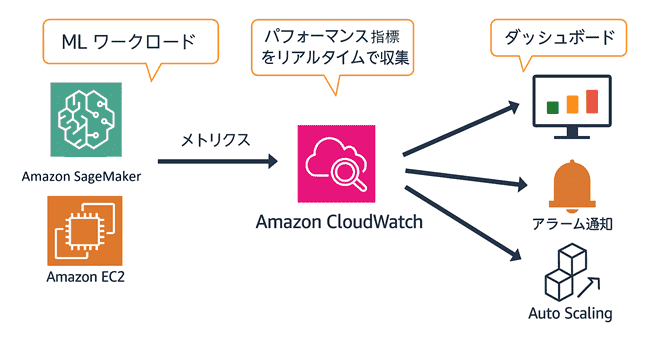
ある企業は、Amazon Bedrock で基盤モデル (FM) を使用する生成 AI アプリケーションの応答精度を向上させたいと考えています。
これらの要件を最もコスト効率よく満たすソリューションを選択してください。
プロンプトエンジニアリングを使用します。 | |
FM を再トレーニングします。 | |
新しい FM をトレーニングします。 | |
FM をファインチューニング (微調整) します。 |
問題 7 の説明および補足
プロンプトエンジニアリング
「プロンプトエンジニアリング」 により FM を再トレーニングせずに応答精度を向上でき、追加コストを最小化できるため正解です。
00:00
| 手法名 | 概要 | 主な用途・例 |
|---|---|---|
| 思考の連鎖 (Chain-of-Thought) | 複雑なタスクを細分化し、ステップごとのプロンプトを作成して解決を導く手法。 | ・問題解決の手順を一歩ずつ説明する応答 ・「次のステップは何ですか?」を繰り返しながら進める |
| ゼロショット (Zero-shot) | 例を示さずに、タスクに関する説明のみを提示する手法。 | ・単純な命令や質問: 「次の文を翻訳してください。」 ・直接的なタスク指定 |
| シングルショット (Single-shot) | モデルに応答の例を1つ提示することで、望ましい回答パターンを誘導する手法。 | ・例: 質問に対する模範回答を1例だけ提示 |
| フューショット (Few-shot) | モデルに応答の例を複数提示することで、望ましい回答パターンを誘導する手法。 | ・例: 質問に対する複数の模範回答を提示 ・「次の形式に従って答えてください」 |
| プロンプトテンプレート | モデルがタスクや制約を理解するために使用する構造化された指示のセットを利用する手法。 | ・テンプレートに基づいた特定の形式やスタイルの応答 ・「以下の形式で答えてください」 |
問題は全部で 7 問。全て答えられるように頑張りましょう!
|
リスト |
